C++ gives you precise control over object lifetime and placement—but that control comes with responsibility. When people say “stack vs heap,” they’re often mixing three different ideas:
- Storage duration (language rule): When an object’s lifetime begins/ends (automatic, dynamic, static, thread).
- Allocation API (how bytes are obtained):
new/delete,new[]/delete[], allocators,malloc/free, PMR resources, etc. - Memory region (implementation detail): where those bytes typically come from in a native process (stack pages, heap arenas, static segments, mapped pages).
This post focuses on typical desktop/server ABIs (e.g., mainstream Windows/Linux/macOS toolchains). It assumes you’re comfortable with basic C++ object lifetimes and RAII. Examples reflect common implementations, but details are ABI-, OS-, and compiler-dependent.
Terminology (quick callout)
To reduce ambiguity, here’s how the terms will be used:
- Stack: usually the thread stack region used for call frames.
- Heap: the process’s dynamic allocation region(s) managed by an allocator (often multiple arenas/heaps).
- Free store (C++ term): the abstract pool used by
operator new/operator delete(often backed by “the heap,” but not required). - Storage duration: automatic / dynamic / static / thread (defined by the C++ standard).
- Object lifetime: the period during which it’s valid to use an object (begins after initialization, ends at destruction).
- Scope: where a name is visible; related to but not the same as lifetime.
A mental model of a process’s memory (illustrative)
Most platforms implement a process virtual address space with several regions. The exact layout varies due to ASLR, guard pages, different stack growth directions, multiple heaps/arenas, memory-mapped files, and sometimes JIT/codegen pages.
Figure 1 is illustrative, not a promise of exact addresses or ordering.
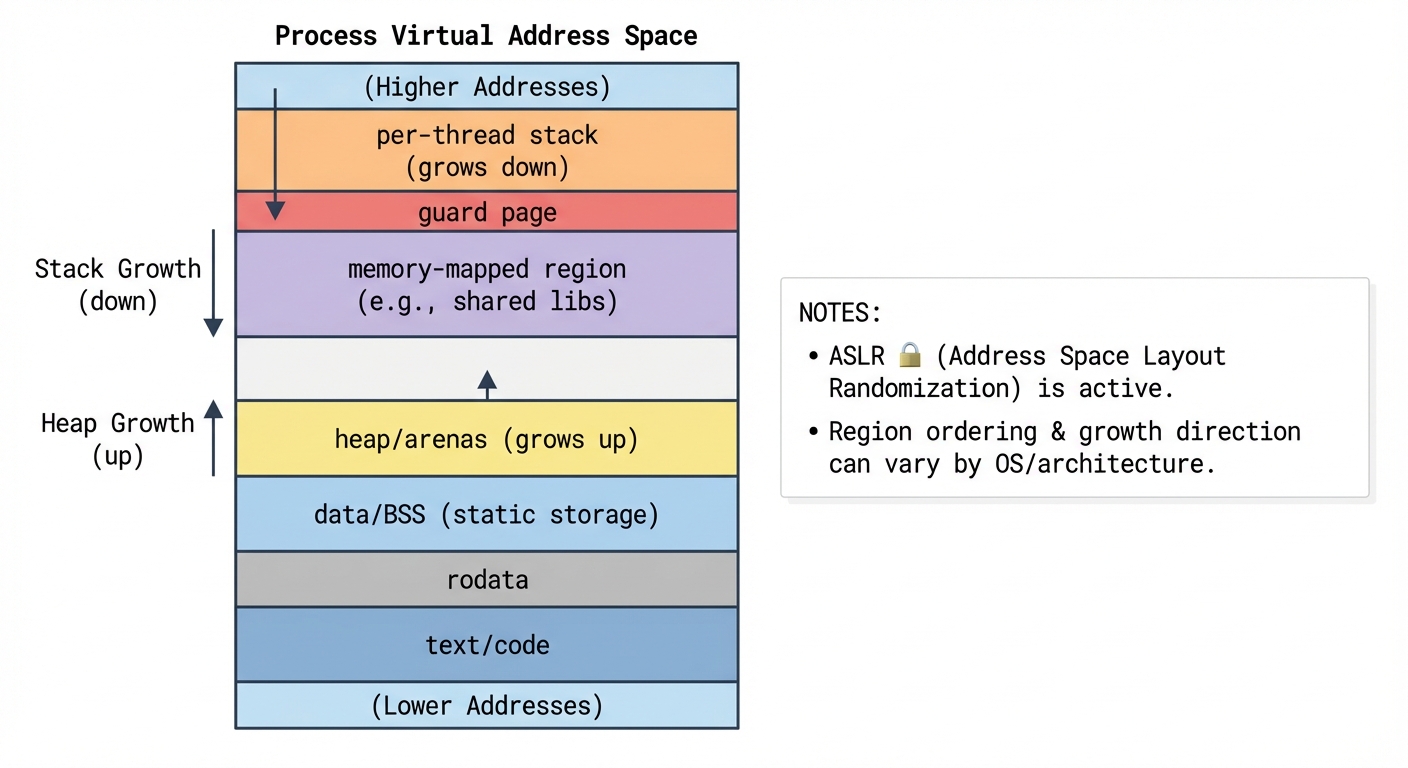
Figure 1: Illustrative process virtual memory regions (exact layout varies by OS/ABI, ASLR, and runtime).
Key regions you’ll hear about:
- Text (code) segment: compiled machine code.
- Read-only data: constants, string literals (often).
- Static storage (data/BSS): globals, namespace-scope variables,
staticlocals. - Heap / arenas: dynamically allocated memory managed by an allocator.
- Stack: call frames for function calls (locals, saved registers, return address).
Important: “stack” here means the thread stack. Each thread has its own stack; dynamic allocation is typically shared process-wide (with synchronization inside the allocator).
Stack vs heap: the real differences
The most practical differences are lifetime, ownership, and allocation/deallocation mechanics.
Also note two common misconceptions up front:
- Automatic storage duration ≠ guaranteed stack placement. Compilers can keep objects in registers, optimize them away, or move them when it’s safe.
- “Heap” is an implementation bucket; C++ talks about the free store.
newallocates from the free store viaoperator new, which may usemalloc, may use a different allocator, or may be replaced.
Automatic storage duration (often stack-like)
When you write:
void f() {
int x = 42; // automatic storage duration
std::string s = "hi";
}
xandshave automatic storage duration.- They are created when execution enters the block and destroyed when it leaves.
- Their storage is often in the thread’s stack frame, but the compiler may:
- keep them in registers,
- elide them entirely,
- or otherwise avoid a stable address unless it must materialize one.
Automatic objects are attractive because destruction is deterministic at scope exit (RAII), and allocation is typically very cheap.
Dynamic storage duration (free store; commonly backed by heap arenas)
When you write:
auto p = new int(42);
// ...
delete p;
- The
inthas dynamic storage duration. - It lives until you destroy it with
delete(or, preferably, let a smart pointer own it). - Allocation happens via
operator new(and deallocation viaoperator delete). The implementation may callmalloc/free, but it’s not required.
Dynamic allocation is flexible (lifetime not tied to a scope), but it can be slower, can fragment, and is easier to misuse if managed manually.
“Where is the object stored?” vs “what does the object own?”
A key mental shift: an object can live in one place (often automatic storage) while managing memory somewhere else (often dynamic storage).
Example:
void g() {
std::vector<int> v;
v.push_back(1);
v.push_back(2);
}
v(thestd::vectorobject itself) is typically an automatic object (often residing in the stack frame).- An empty vector typically allocates nothing.
- The vector’s elements are stored in a dynamically allocated buffer only once it needs capacity (growth triggers allocation and sometimes reallocation).
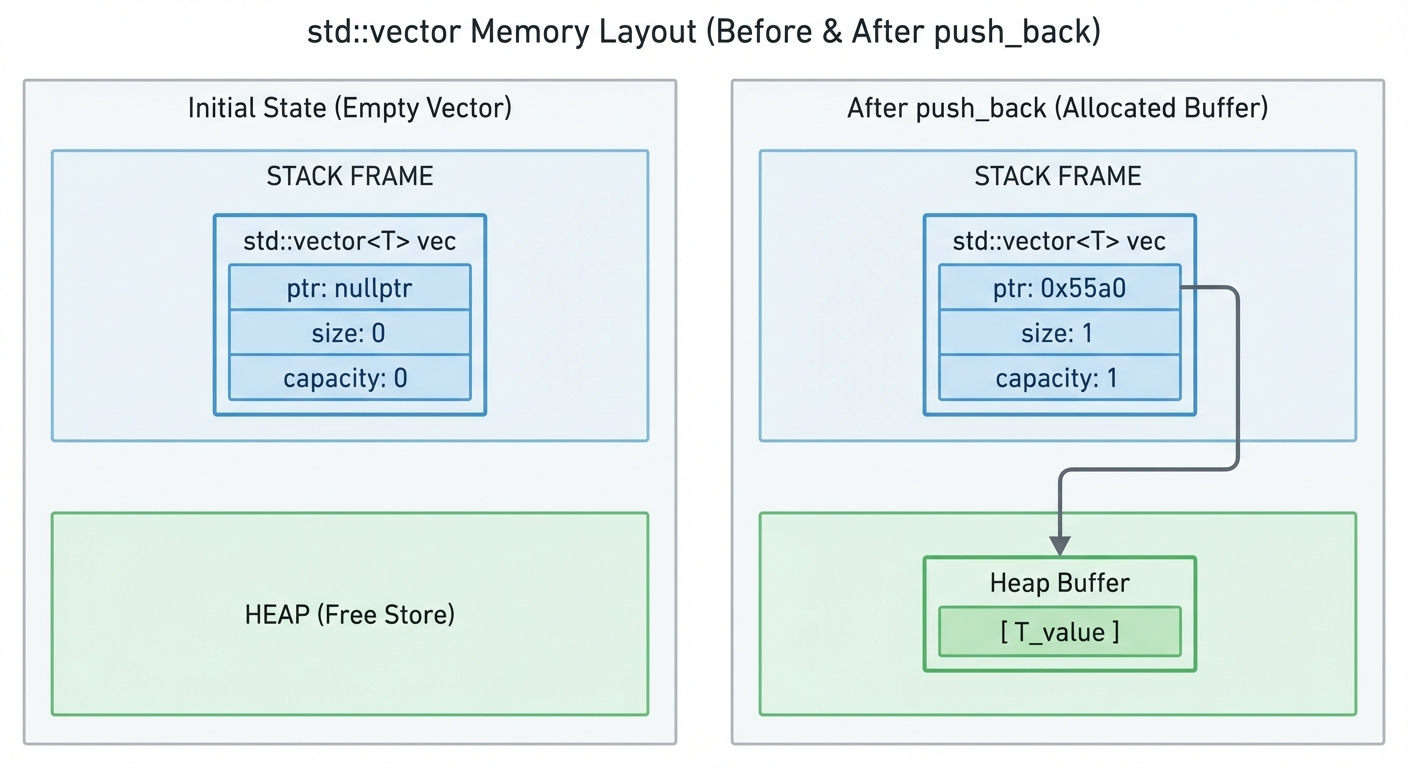
Figure 2: A small std::vector object (pointer/size/capacity) vs its dynamically allocated element buffer.
If you want fewer allocations, the canonical tool is:
std::vector<int> v;
v.reserve(1024); // allocate once (typically), then grow into it
This “small header + separate buffer” pattern is common:
std::string(often has Small String Optimization, not guaranteed)std::vector,std::map,std::unordered_mapstd::function(may have a small-buffer optimization, not guaranteed)
Quick experiment #1: print some addresses
This won’t prove “what is stack vs heap” in a formal sense, but it makes the typical regions tangible.
#include <iostream>
#include <vector>
int global = 123;
int main() {
int local = 7;
auto p = new int(42);
std::vector<int> v;
v.push_back(1);
std::cout << "&global: " << (void*)&global << "\n";
std::cout << "&local: " << (void*)&local << "\n";
std::cout << "p (new): " << (void*)p << "\n";
std::cout << "v.data():" << (void*)v.data() << "\n";
delete p;
}
On many systems you’ll see &local cluster near other stack addresses, while p and v.data() cluster in allocator-managed regions, and &global elsewhere.
Object layout basics: what bytes make up an object?
At the machine level, an object is a contiguous region of bytes whose layout follows the C++ object model plus platform ABI rules. Do not assume exact sizes/offsets across compilers or targets. The examples below are typical, e.g., on LP64 (Linux/macOS x86-64) where sizeof(void*) == 8.
Plain structs: fields laid out with padding
struct A {
char c;
int i;
};
A common layout is:
cat offset 0- padding bytes for alignment
iat the nextalignof(int)boundary
So sizeof(A) is often 8, not 5.
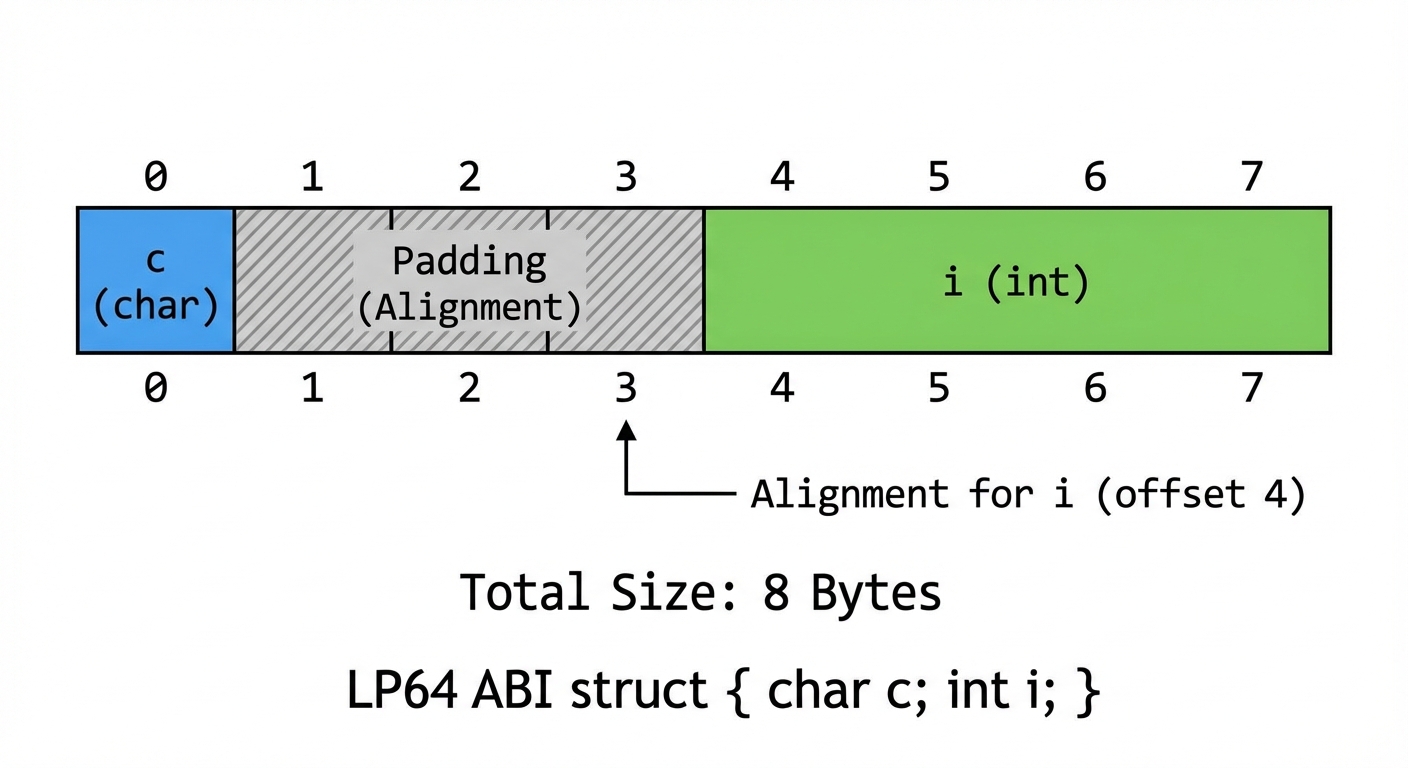
Figure 3: Typical padding/alignment in a simple struct (example assumes common LP64 alignment rules).
Takeaways:
- Alignment can insert padding between members.
- Member order affects size and cache friendliness.
Classes with virtual functions: vptr and vtable (typical)
struct B {
virtual void foo();
int x;
};
Many implementations add a hidden pointer (often called a vptr) inside each object, pointing to a vtable typically stored in a read-only region.
Caveats:
- The vtable being in read-only memory is typical, not mandated.
- Multiple inheritance and virtual inheritance can introduce multiple vptrs, pointer adjustments, and thunks. The simple “one vptr at the start” mental model is not universal.
Arrays and new[]: what’s different?
Single-object new constructs one object; new[] constructs N objects and delete[] must destroy N objects.
auto p = new Widget[10];
// ...
delete[] p;
In many implementations, the allocation for new[] includes extra metadata (often called an “array cookie”) so delete[] knows how many destructors to run. This cookie is an implementation detail:
- It may exist, or may be represented differently.
- It’s one reason
new[]must pair withdelete[].
This connects directly to the rule: mixing new[] with delete is undefined behavior.
Storage duration categories (beyond stack vs heap)
C++ defines storage duration more precisely than “stack/heap.”
Automatic storage duration
- Local variables (non-
static) inside blocks. - Often stack-backed, but not guaranteed.
Dynamic storage duration
- Objects created by
new/new[]. - Uses the free store via
operator new.
Static storage duration
- Namespace-scope variables,
staticclass members, andstaticlocals.
int global2 = 1;
void h() {
static int counter = 0;
++counter;
}
Notes that matter in real code:
- Static initialization order fiasco: initialization order across translation units is not what you want to depend on.
- Prefer function-local statics for lazy initialization; since C++11, initialization of function-local statics is thread-safe.
Thread storage duration
thread_localvariables.
thread_local int tls = 0;
Each thread gets its own instance. Destruction typically happens at thread exit, but there are nuances (e.g., thread termination during program shutdown, or DLL/shared-library unload scenarios). TLS can also have performance/size implications depending on platform.
What actually goes into a stack frame? (typical)
A stack frame (activation record) commonly holds:
- Return address
- Saved registers
- Function parameters (sometimes)
- Local variables (that aren’t optimized away)
- Spill slots (compiler temporaries)
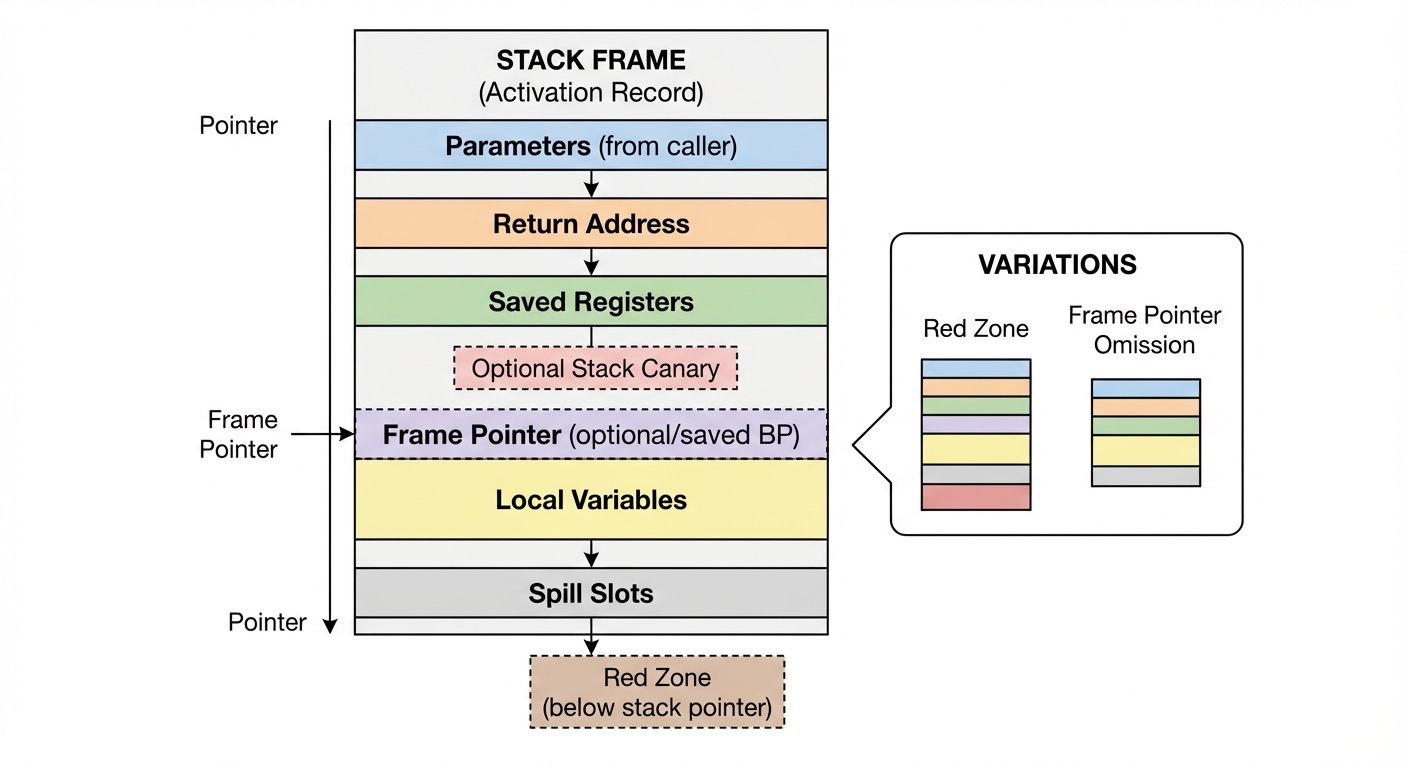
Figure 4: Typical stack frame contents (actual layout varies: red zones, stack canaries, and frame-pointer omission can change what you observe).
More reasons the diagram may not match reality:
- Red zone (some ABIs allow leaf functions to use space below the stack pointer without adjusting it)
- Stack canaries (stack-smashing protection)
- Frame pointer omission (no dedicated frame pointer register)
Practical implication: “stack memory” is useful for lifetime reasoning, but not a guarantee of a stable address for every local under optimization.
Also, a caveat about teaching vs correctness: “taking the address of a local forces it to have storage” is a decent intuition, but optimizers can still surprise you (especially with inlining and escape analysis). Don’t use tricks like volatile to “force” layout for correctness; use them only in experiments/debug builds.
Pointers, references, and lifetime traps
Pointers
A pointer variable is just an object that stores an address.
int x = 7;
int* p = &x;
xis anintobject.pis a separate object holding the address ofx.pitself can have automatic/static/dynamic storage depending on where it’s declared/allocated.
References
A reference is an alias at the language level. It’s often implemented like a pointer, but you should reason about it as an alias with restrictions (must be bound, cannot be reseated).
A common misconception: a reference member does not extend lifetime.
struct R {
const std::string& ref;
};
R make_bad() {
return R{std::string("temp")}; // ref dangles after this full-expression
}
The temporary string is destroyed at the end of the full-expression; ref becomes dangling.
(Separately: binding a temporary to a const reference local variable can extend the temporary’s lifetime to the reference’s lifetime—but that rule doesn’t “magically” apply through reference members.)
Common pitfalls and how to avoid them
Returning pointers/references to automatic objects
int* bad_ptr() {
int x = 42;
return &x; // dangling pointer
}
int& bad_ref() {
int x = 42;
return x; // dangling reference
}
x is destroyed when the function returns.
Prefer returning by value:
int good() {
int x = 42;
return x; // copy elision is mandatory in some cases since C++17
}
Manual new/delete
If you must allocate dynamically, prefer RAII:
auto p = std::make_unique<int>(42);
Rule of thumb:
- Use
std::unique_ptrby default (single owner). - Use
std::shared_ptronly when you truly need shared ownership.
Mixing allocation and deallocation APIs (undefined behavior)
Pairs must match:
new↔deletenew[]↔delete[]malloc↔free
It’s also undefined behavior to delete memory that came from a custom allocator that doesn’t use operator delete, or to free memory allocated by new.
“Heap” isn’t one thing: arenas, pools, and PMR
Even when you write code that looks heap-allocating, the bytes may come from a specific arena/pool.
One concrete example is std::pmr (polymorphic memory resources). Here, a vector allocates from a monotonic arena backed by a user-provided buffer:
#include <array>
#include <memory_resource>
#include <vector>
int main() {
std::array<std::byte, 4096> arena;
std::pmr::monotonic_buffer_resource rsrc(arena.data(), arena.size());
std::pmr::vector<int> v{&rsrc};
v.reserve(200); // allocations come from rsrc (often from arena first)
v.push_back(1);
}
This reinforces the distinction:
- The allocation API is “vector needs memory.”
- The allocator/resource decides where bytes come from.
- The memory region might be a stack buffer, a static buffer, or a heap arena.
Advanced caveat: escape analysis and stack-allocation of “dynamic-looking” objects
Compilers can sometimes transform code so that something that appears to allocate dynamically doesn’t actually allocate at runtime (or the allocation is short-circuited), if the object doesn’t “escape” and the optimizer can prove it.
Examples include:
- eliding allocations in small cases,
- scalar replacement of aggregates,
- promoting allocations to stack-like storage in limited scenarios.
You generally shouldn’t rely on this for correctness, but it’s another reason syntax alone doesn’t always tell you “where bytes are.”
Performance notes: stack is fast, but not “free”
- Automatic allocation is usually very fast.
- But large automatic objects can overflow the stack (especially with deep recursion or small thread stacks).
Example: this creates a huge automatic object:
void big() {
int huge[10'000'000];
}
Stack sizes differ drastically across OSes and thread configurations. Prefer an idiomatic container for large dynamic buffers:
std::vector<int> buf(10'000'000);
Or when you need a raw array with RAII:
auto buf = std::make_unique<int[]>(10'000'000);
Heap allocations can often be improved by reserving capacity (vector::reserve), using arenas/pools, or selecting appropriate allocators.
Quick experiment #2: observe vector reallocation
This shows when the buffer moves as capacity grows:
#include <iostream>
#include <vector>
int main() {
std::vector<int> v;
const int N = 64;
const int* last = v.data();
for (int i = 0; i < N; ++i) {
v.push_back(i);
if (v.data() != last) {
std::cout << "reallocated at size=" << v.size()
<< " capacity=" << v.capacity() << "\n";
last = v.data();
}
}
}
Try adding v.reserve(N); and observe how reallocations change.
Putting it together: a quick checklist
When you see an object in C++, ask:
- What is its storage duration? (automatic, dynamic, static, thread)
- Who owns it and who destroys it? (scope, smart pointer, program/thread lifetime)
- Does it manage additional memory? (vector/string/function often do)
- Do I store it by value, pointer, or reference? (impacts lifetime and copying)
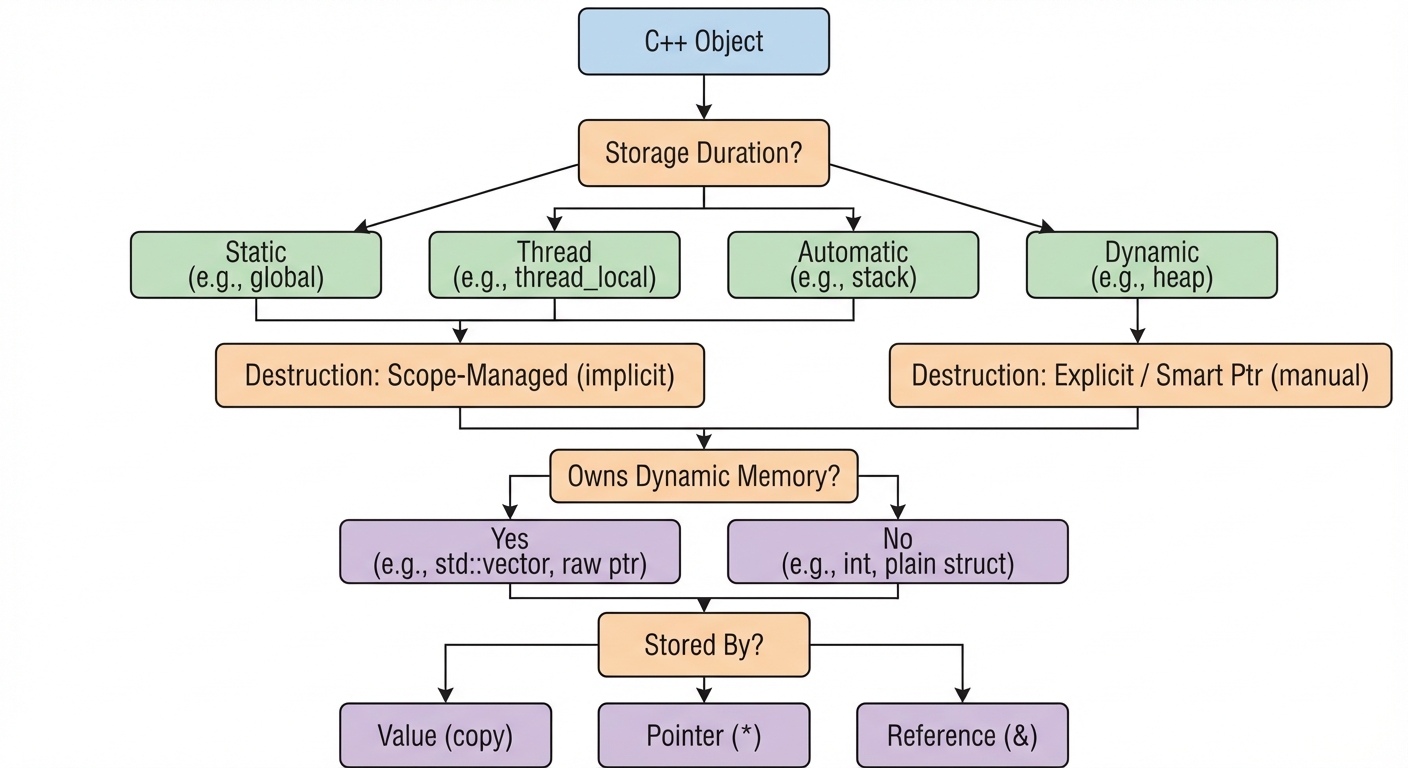
Figure 5: Checklist for reasoning about lifetime (storage duration), ownership, and “object vs owned memory.”
Summary
“Stack vs heap” is useful shorthand, but accurate reasoning in C++ comes from separating:
- Storage duration (language): when lifetime begins/ends.
- Allocation API (mechanics): how bytes are requested and released.
- Memory region (implementation): where those bytes happen to come from.
Key takeaways:
- Automatic objects are destroyed at scope exit—fast and deterministic, but not guaranteed to be physically “on the stack.”
- Dynamic objects live until you destroy them—flexible, but easier to misuse.
- Many types are small headers stored in one place (often automatic) that own buffers elsewhere (often dynamic).
Once you separate where the object is from what the object owns, memory layout becomes much easier to reason about—and your code becomes safer and faster as a result.