Modern C++ gives you several ways to run work concurrently: raw threads, synchronization primitives like mutexes and condition variables, and higher-level task-based APIs like std::async. They can all solve real problems—but each comes with trade-offs.
This post focuses on practical usage: how to start threads safely, protect shared state, avoid deadlocks in everyday code, and use std::async/futures for simpler “run this and give me the result” workflows.
Quick decision table (skim first)
| Tool | What it is | Use it when | Common footguns |
|---|---|---|---|
std::thread / std::jthread | A real thread of execution (OS thread) | You need explicit, long-lived control (background loop, service thread, dedicated worker) | Forgetting to join (terminates), capturing dangling refs, ad-hoc cancellation |
std::mutex + std::condition_variable | Synchronization for shared state + coordination | You must share mutable state or implement producer/consumer queues | Deadlocks, contention, notifying without holding the right mutex/state |
std::async + std::future | Task that yields a result (and transports exceptions) | One-off “compute and return” tasks; simple fan-out/fan-in | Deferred execution surprises; future destructor blocking; launching too many tasks |
Rule of thumb: Prefer the highest-level tool that fits. Move down the stack only when you need more control.
What we won’t cover (so expectations match)
To keep this practical and focused, we won’t dive deep into:
- Atomics and memory ordering details (beyond a brief mention)
- Lock-free data structures
- Building a full thread pool / work-stealing scheduler
- NUMA, affinity, and OS-level scheduling knobs
When you actually need concurrency
Concurrency helps when:
- You have independent work that can run in parallel (e.g., processing chunks of data).
- You need to keep a responsive thread (UI thread or main loop) while doing background work.
- You’re waiting on I/O (network/disk) and can overlap waiting with other work.
It hurts when:
- Tasks are tiny and overhead dominates.
- You share lots of mutable state (locking becomes the bottleneck).
- You “parallelize” something that’s fundamentally sequential.
A good mental model is: maximize independent work; minimize shared mutable state.
std::thread: the low-level building block
What it is
std::thread represents an OS thread of execution. It’s powerful, but it puts lifetime management on you.
Minimal example
#include <thread>
#include <iostream>
void worker(int id) {
std::cout << "worker " << id << "\n";
}
int main() {
std::thread worker_thread(worker, 1);
worker_thread.join();
}
When to use
Use std::thread when you need explicit control over a thread’s lifetime (e.g., a long-running loop), or when you’re implementing your own higher-level concurrency abstraction.
Common footguns (lifetime hazards)
Key rule: a joinable std::thread must be join()ed or detach()ed before destruction.
If a joinable thread is destroyed, the program calls std::terminate().
Concrete failure mode (early return / exception path):
#include <thread>
void do_work();
int main() {
std::thread t(do_work);
if (/* error */ true) {
return 1; // oops: t is still joinable -> std::terminate()
}
t.join();
}
Callout — “Join or terminate”: If you see
std::threadas a local variable, mentally check every exit path (returns, exceptions) for a guaranteedjoin().
Prefer RAII for joining (C++20 std::jthread) + stop tokens
If you have C++20, std::jthread is usually the better default: it joins automatically on destruction and supports cooperative cancellation via std::stop_token.
#include <thread>
#include <chrono>
int main() {
std::jthread t([](std::stop_token st) {
while (!st.stop_requested()) {
// do periodic work
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
// cleanup before exit
});
// ... later
t.request_stop(); // asks the thread to stop (cooperative)
} // auto-join at scope exit
Callout — Prefer structured concurrency:
std::jthread+ stop tokens tends to produce code that shuts down cleanly and predictably.
Passing data safely (ownership vs. synchronization)
Be explicit about ownership and lifetimes:
- Use values for small immutable inputs.
- Use
std::shared_ptrwhen multiple threads need shared ownership. - Use
std::ref(x)only when you are surexoutlives the thread.
Important nuance: shared ownership is not synchronization. A shared_ptr keeps an object alive, but it does not make concurrent mutation safe.
Example (shared ownership, read-only access):
#include <thread>
#include <memory>
#include <vector>
#include <cstddef>
int main() {
auto data = std::make_shared<const std::vector<int>>(1'000'000, 42);
std::thread t([data] {
// Safe: read-only access
int first = (*data)[0];
(void)first;
});
t.join();
}
If you need to mutate shared data, you still need coordination (mutex, atomics, or ownership transfer).
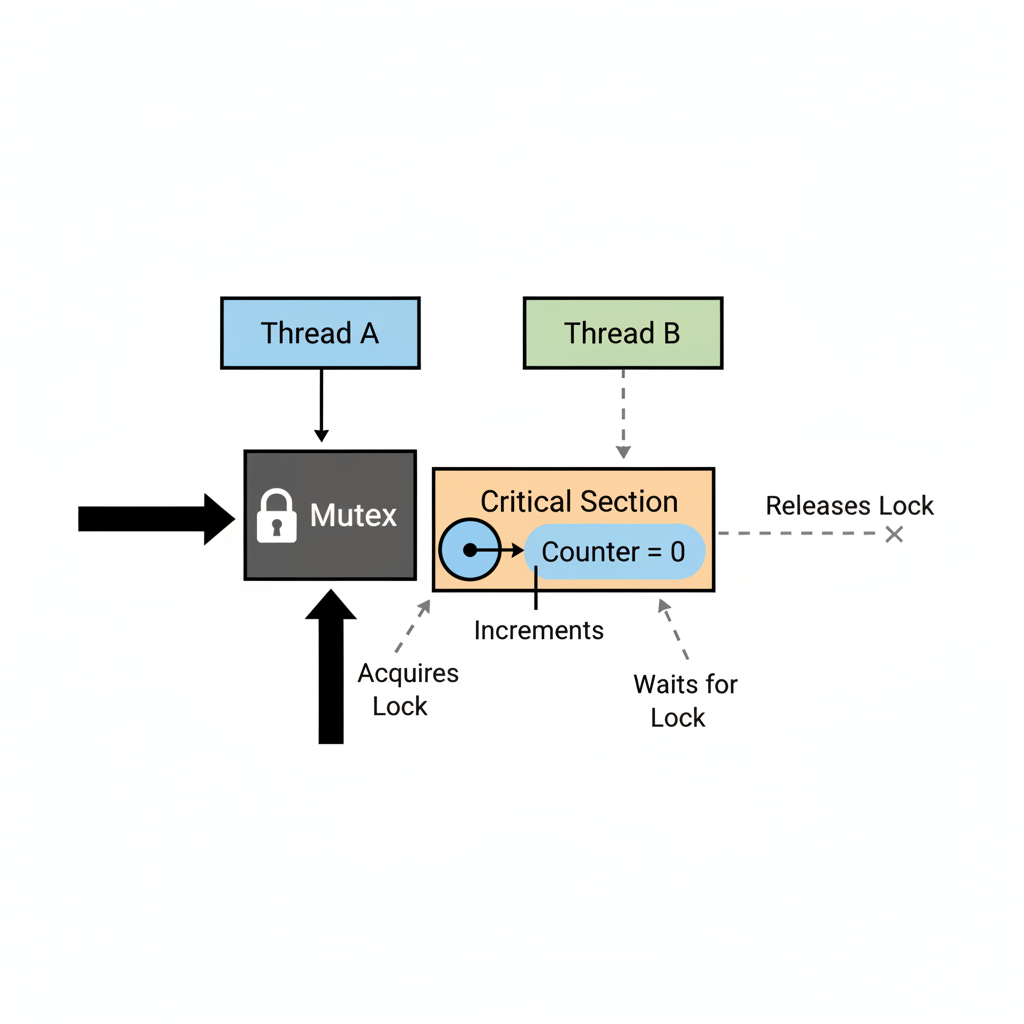
Mutexes (and condition variables): protecting shared state
What it is
A mutex serializes access to a critical section. In C++, you almost always want to lock via RAII.
Correctness vs performance:
- A mutex primarily gives correctness (prevents data races / UB).
- Contention is the performance cost (throughput drops when many threads fight over the same lock).
Note on visibility:
mutexlock/unlock establishes a happens-before relationship—writes made while holding the lock become visible to a thread that later acquires the same lock.
Minimal example (std::mutex + std::lock_guard)
This is a correctness demo (not the best way to implement a counter):
#include <mutex>
#include <thread>
std::mutex m;
int counter = 0;
void increment_counter() {
std::lock_guard<std::mutex> lock(m);
++counter;
}
int main() {
std::thread a([]{
for (int i = 0; i < 100000; ++i) increment_counter();
});
std::thread b([]{
for (int i = 0; i < 100000; ++i) increment_counter();
});
a.join();
b.join();
}
In real code, a simple counter is often better as std::atomic<int> (when all you need is increment/read), because it avoids lock contention.
Reducing lock contention (performance)
Common techniques:
- Shrink the critical section: do work outside the lock.
- Avoid holding locks while doing I/O.
- Use per-thread local accumulation then merge once.
- Consider atomics for simple counters/flags (when appropriate).
If performance matters, measure and profile (many profilers can show mutex contention hotspots).
Example: minimize time under lock.
#include <mutex>
#include <vector>
std::mutex m;
std::vector<int> shared;
void produce_batch() {
std::vector<int> local;
local.reserve(1024);
// expensive work without lock
for (int i = 0; i < 1024; ++i) {
local.push_back(i);
}
// short lock to publish
{
std::lock_guard<std::mutex> lock(m);
shared.insert(shared.end(), local.begin(), local.end());
}
}
Callout — Never hold a lock across I/O or callbacks: I/O may block for a long time; callbacks may re-enter code that tries to take the same lock.
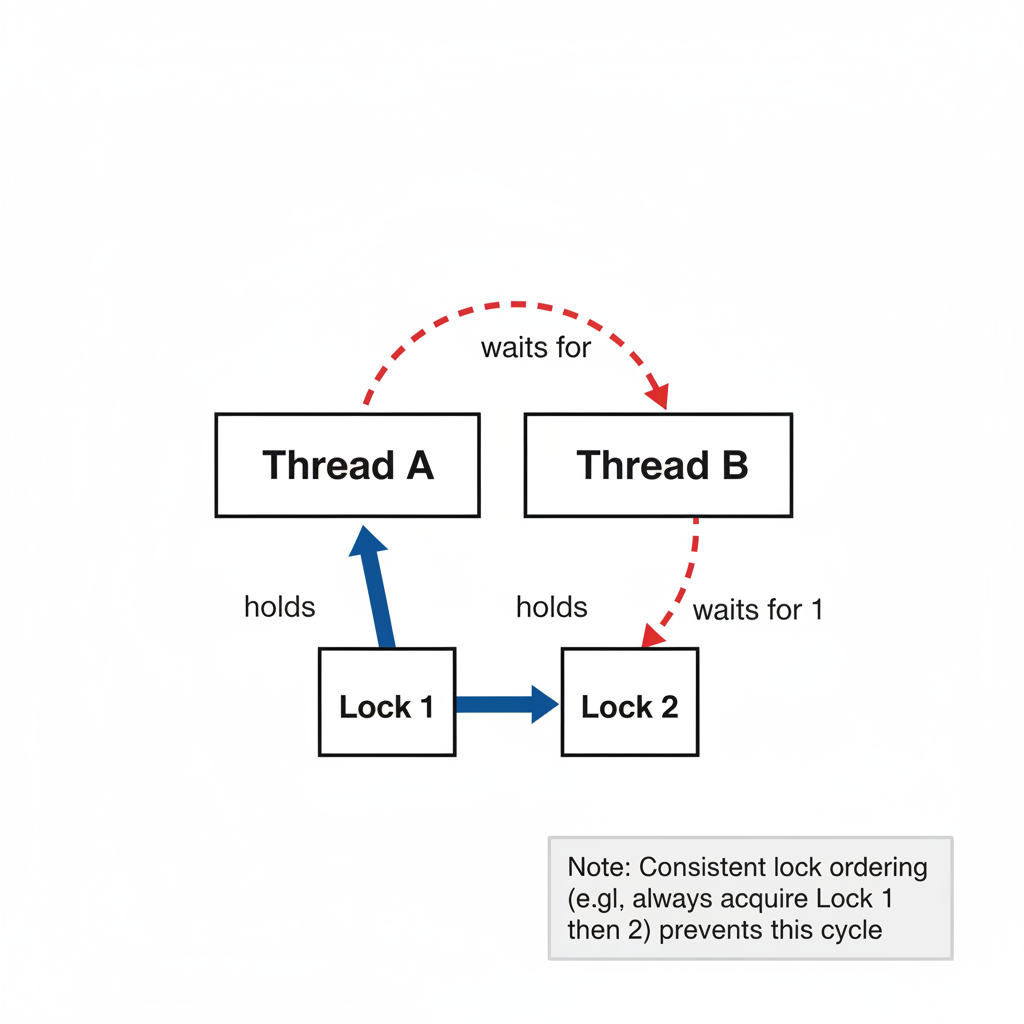
Avoiding deadlocks
Deadlocks happen when threads acquire multiple locks in different orders.
Practical checklist:
- Establish a global lock order and follow it everywhere.
- Document that order near the mutex declarations (a simple comment helps).
- Prefer locking at the “leaf” layer (keep lock acquisition close to the data).
- Avoid calling into unknown code while holding multiple locks.
- When locking multiple mutexes, use
std::scoped_lock(C++17) orstd::lock.
#include <mutex>
std::mutex m1, m2;
void safe_transfer() {
std::scoped_lock lock(m1, m2); // deadlock-avoiding acquisition
// operate on resources protected by m1 and m2
}
Condition variables for “wait until”
If one thread must wait for a condition (e.g., queue not empty), don’t busy-wait. Use std::condition_variable.
Two key rules:
- Always protect the shared state with the same mutex used by the condition variable.
- Always wait in a loop (or use the predicate overload). The predicate form is equivalent to a
whileloop and is required due to spurious wakeups.
Minimal producer/consumer with a clear shutdown path:
#include <condition_variable>
#include <mutex>
#include <queue>
std::mutex m;
std::condition_variable cv;
std::queue<int> q;
bool done = false;
void producer() {
{
std::lock_guard<std::mutex> lock(m);
q.push(1);
}
cv.notify_one();
}
void request_shutdown() {
{
std::lock_guard<std::mutex> lock(m);
done = true;
}
cv.notify_all();
}
void consumer_loop() {
std::unique_lock<std::mutex> lock(m);
while (true) {
cv.wait(lock, [] { return done || !q.empty(); });
if (done && q.empty()) {
break; // clean shutdown
}
int x = q.front();
q.pop();
lock.unlock();
// process x without holding the lock
(void)x;
lock.lock();
}
}
Note on visibility: the mutex used with
wait()/notify_*()is what makes state changes (likedone = true) reliably visible to the waiting thread.
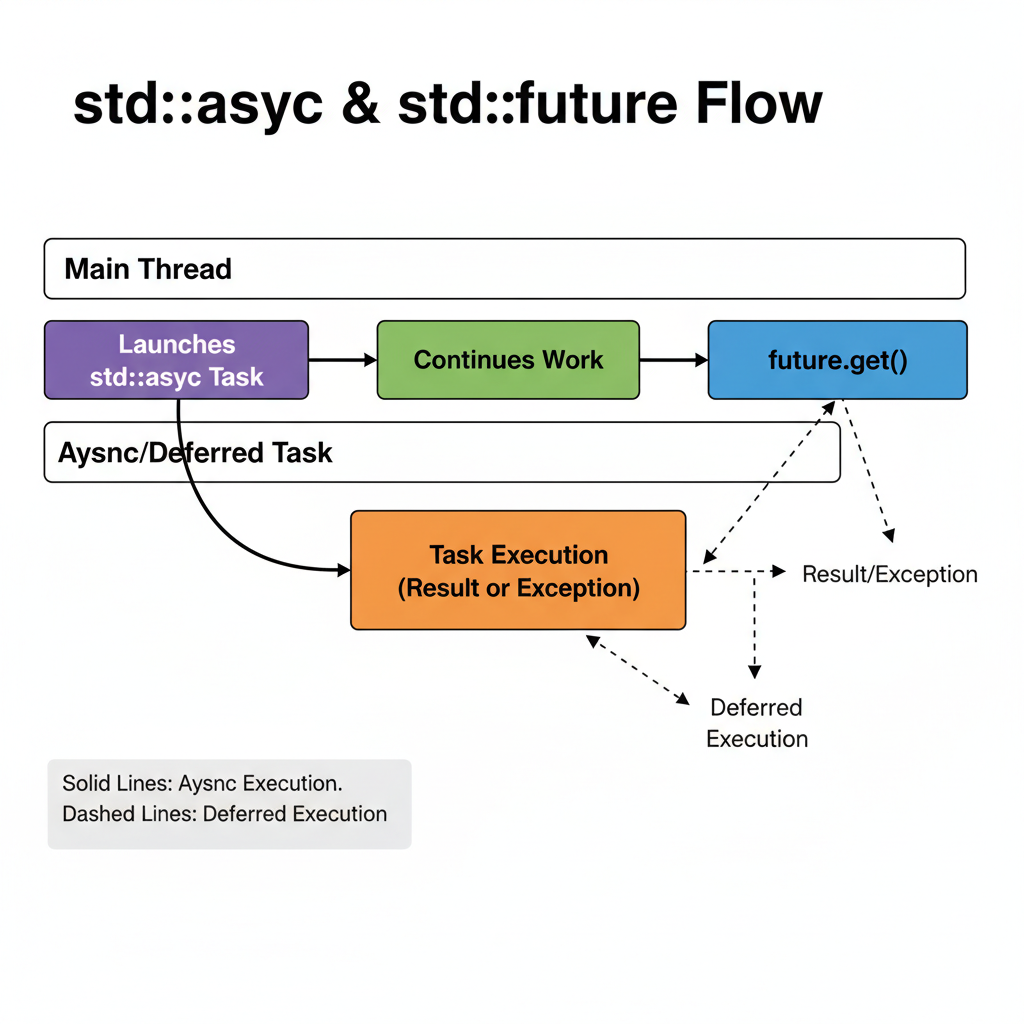
std::async and futures: task-based concurrency
What it is
std::async runs a callable and returns a std::future<T> for its result. This is often simpler than manually managing threads.
Minimal example
#include <future>
#include <string>
std::string fetch() {
// pretend this does I/O
return "data";
}
int main() {
auto fut = std::async(std::launch::async, fetch);
// do other work...
std::string result = fut.get(); // waits and retrieves
}
When to use
- You need a result.
- You want automatic exception transport.
- You prefer a task abstraction over explicit threads.
Common footguns
Launch policy: deferred is real
If you omit the policy, the implementation may choose deferred execution. Deferred means the function runs only when you call get()/wait(), and it runs on the thread that calls get().
#include <future>
#include <iostream>
int main() {
auto fut = std::async(std::launch::deferred, [] {
std::cout << "runs on get()\n";
return 123;
});
// no work has run yet
int x = fut.get();
(void)x;
}
Use std::launch::async when you want to force asynchronous execution.
Future destructor may block (surprising)
With std::launch::async, many standard library implementations will block in the future’s destructor if you never call get() or wait().
Practical guidance: always consume futures (call get()/wait()), or store them somewhere that you intentionally join later.
Error propagation is a feature
Exceptions thrown inside the async task are rethrown when you call future::get().
#include <future>
#include <stdexcept>
int main() {
auto fut = std::async(std::launch::async, []() -> int {
throw std::runtime_error("boom");
});
try {
(void)fut.get();
} catch (const std::exception&) {
// handle
}
}
When std::async is not enough
- You need a long-lived worker thread or a thread pool.
- You need precise control over scheduling/affinity.
- You need to launch many tasks efficiently (a custom pool is often better).
Choosing between threads, mutexes, and async (expanded)
A practical decision guide:
- Use
std::async+std::futurewhen you want “compute this and give me the result”, especially for one-off tasks. - Use
std::thread/std::jthreadwhen you need explicit control over a thread’s lifetime (long-running loops, background services). - Use mutexes/condition variables when you must share mutable state or coordinate producers/consumers.
Also consider:
- Prefer message passing (queues) over sharing complex structures.
- Prefer immutable data and ownership transfer where possible.
Common pitfalls (and how to avoid them)
- Data races: any unsynchronized read/write of shared data is undefined behavior. Protect with mutexes or atomics.
- Dangling references: passing references to threads without guaranteeing lifetime.
- Detached threads: the program may exit while they still run; resources may be destroyed.
- Locking around callbacks: calling unknown code while holding a lock can cause re-entrancy deadlocks.
- Assuming parallel speedup: measure; contention and memory bandwidth can dominate.
A practical mini-pattern: parallel map with async
For small-to-medium numbers of tasks, std::async can be a clean solution:
#include <future>
#include <vector>
int work(int x) {
return x * x;
}
std::vector<int> parallel_map(const std::vector<int>& in) {
std::vector<std::future<int>> futs;
futs.reserve(in.size());
for (int x : in) {
futs.push_back(std::async(std::launch::async, work, x));
}
std::vector<int> out;
out.reserve(in.size());
for (auto& f : futs) out.push_back(f.get());
return out;
}
Scalability caveat: launching N async tasks may create up to N threads depending on the implementation and policy. For large task counts, consider:
- batching inputs (coarser tasks)
- limiting concurrency (e.g., a semaphore)
- using a thread pool
- using parallel algorithms (
<execution>) where applicable
Final checklist
- Use RAII for thread and lock lifetimes (
std::jthread,std::lock_guard,std::unique_lock). - Remember: shared ownership is not synchronization.
- Minimize shared mutable state; keep critical sections short.
- Use
std::scoped_lockfor multiple mutexes, and document lock ordering. - Use condition variables to wait efficiently; predicate-
waitis the “while loop” rule. - Prefer
std::asyncwhen you want results + exception propagation with minimal plumbing—but always consume futures. - Measure performance and contention; don’t assume.
Further reading
std::thread: https://en.cppreference.com/w/cpp/thread/threadstd::jthread: https://en.cppreference.com/w/cpp/thread/jthreadstd::mutex: https://en.cppreference.com/w/cpp/thread/mutexstd::condition_variable: https://en.cppreference.com/w/cpp/thread/condition_variablestd::async: https://en.cppreference.com/w/cpp/thread/async- Book: C++ Concurrency in Action (Anthony Williams)